
Numeracy
TLDR: Numeracy is (like literacy) an educational priority in Utopia. Tests are, by default, graded using odds-ratios.
Prerequisites: Opinions
The written word has changed the world in uncountable ways. From street signs to great works of literature, it’s hard to imagine a world without words. The written word has been around for about three thousand years, but for most of that time literacy was limited to scribes, priests, tax-collectors, and other (typically male) experts. Only around 1600 did that start to change on a large-scale. Starting in Britain and the Netherlands, and then sweeping into the rest of Europe, populations gradually became literate as the centuries passed. Then, in the 20th century, things started to rapidly change, and today only about 13% of the world population is illiterate, mostly restricted to the poorest countries.

Literacy is important, not just because of the benefit to individuals, but from the network effects for societies. A literate populace can be expected to read signs and letters in the mail. New avenues of communication and thought open up, not restricted to the elite.
I believe there is a similar phenomenon that happens in parallel with learning to read: learning to work with numbers. As an analogy to literacy, we can consider the skill of numeracy.
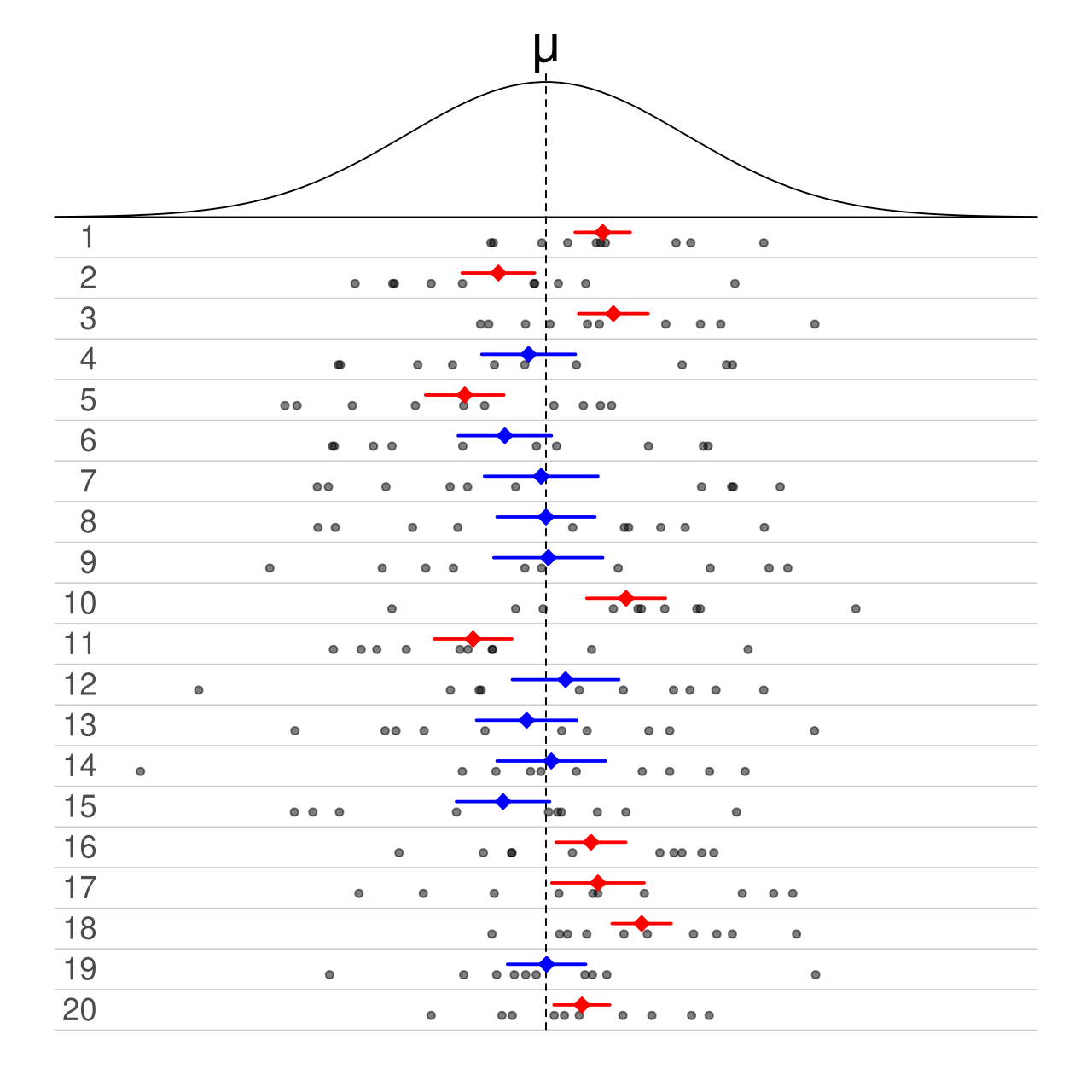
Numeracy, like literacy, is not a binary (despite what the graph above might imply). Almost everyone can do basic counting, but the skill of working with numbers extends far beyond counting and basic arithmetic, just like being literate extends beyond knowing the alphabet and how to read common words. We’ll explore three primary skills of numerate people together, but numeracy is not any of these particular skills, nor even their sum, but rather the gestalt that they fit into.
I also claim that numeracy is not mathematics per se, although most people first start working with numbers in a serious sense in “math class.” Math is its own skill — the art of technical explanation and manipulation of formal systems. Many mathematicians largely work without numbers, and many of the core exercises of the numerate mind are hardly mathematical in nature, though there is of course a deep overlap.
Without wasting more time, let’s dive in to some examples of skills that are familiar and comfortable to a numerate mind…
Estimation
How many fish are there? How many whales are there? In the USA, which group has more money, people who make less than $50k/year or people who make more than $200k? How many ancestors do you have if we go back to the year 1492?
The world is full of numbers. You can see them, if you look. Many of these numbers are important to day-to-day life, and most numbers are not the sorts of things that can be easily looked up on the internet.
How many people will you hug per year if you move to another city? How long will your current project take to complete? How much money will you be earning five years down the road?
When a number can’t be gained from a book, webpage, or other authority, the only real options are to ignore the number, to measure it directly, or to guess. Ignorance doesn’t bring any benefit, but is the most common response. Measurement is nice when possible, but often out of reach. But guessing numerical values is something that’s relatively quick and easy.
Guessing numbers, particularly important ones, is something that weirds many people out or feels dirty in some way. Numerical guesses are often derided as being “ass numbers,” with little bearing on reality. And while it’s absolutely true that not all numbers are equally accurate/precise, there is a real skill to guessing/estimating numerical values. This skill can be trained to the point where the guesses of an expert estimator are much better than those of an innumerate person, even if they’re both equally intelligent.

I know of two keys to good estimation: factored guesstimates, and learning a broad collection of reference quantities.
A factored guesstimate is an estimate that’s arrived at by multiplying many numbers together. This technique is often called Fermi estimation. The way it works is that while any given guess is likely to have error, the direction of the errors for various guesses aren’t likely to be correlated, so as the numbers are combined, the errors will cancel each other out, leading to an estimate that’s more accurate than the parts. One can also use different lines of reasoning and take a weighted average of their results.
For instance: What volume of garbage is thrown away every day in the USA? I’ll estimate this as: (bags I throw away each week)×(how much more does the average person throw away)×(USA population)×(how big is a bag of trash)×(weeks in a day) = 1.2×115%×330,000,000×(20cm×40cm×65cm)×1/7 ≈ 3.4 billion liters/day. Okay, now how good is that estimate? The internet says Americans throw away around 5 pounds of trash per day, and that a liter of trash is about a pound, which comes out to approximately 1.75 billion liters/day. My estimate was about twice the true value, but I was able to generate it quickly without access to anything but a calculator. Perhaps I throw out more trash than the average person, or I think I throw out more than I do, or an average trash bag is smaller than I expect, or some combination of the three. Regardless, it was certainly a much better estimate than if I’d tried to guess the quantity directly!
In making that estimate, I leaned on a fact that I had memorized earlier: the USA has approximately 330 million people. In my experience doing factored estimation, that number shows up a lot (mostly because I live in the USA and am often interested in things like national statistics). A physicist might find it useful to know the mass of a liter of water (1kg), the radius of the Earth (~6.3 thousand km), or the speed of sound (~350m/s). A psychologist might find it useful to know the fraction of people (in the west) who identify as queer (~5% and growing) or the average duration of a depressive episode (3 month median, with long tail). While the specific numbers vary by person, a good estimator will pick up and remember lots of numbers, because each known number serves as a landmark that can help pin down an estimate.
With a bunch of numbers in one’s mind, and lots of practice doing estimation, a world of quantities start to become knowable — not as precise values, but as meaningful numbers nevertheless.
Comparison/Classification
Are you tall or short? A numerate person will reflexively flinch away from a question like this, because it’s attempting to make a quantity into a binary. It’s not like the words “tall” and “short” are meaningless, but they’re often a needless oversimplification. “How tall are you?” is a much better question, in that it leaves open room for a precise answer, rather than flattening one’s view of reality.
Are you strong or weak? This question is harder to notice as an oversimplification, but it’s there just as much as asking about height. Strength is a more nebulous quantity (quantity of push-ups? deadlift max-weight? kick force?) but it’s undoubtably more like a quantity than a binary. There aren’t simply strong and weak people, so much as a spectrum of stronger and weaker people. In the absence of a direct measurement, it’s often useful to fall back on being able to compare people/things against each other. Am I stronger or weaker than my mom? My brother? My boss? A specific celebrity?

One of the most useful techniques for evaluating someone is to imagine them in a room with 100 randomly sampled people, and arrange the room by comparing people on the trait in question. How many people in the room are taller/shorter than you? How many are stronger/weaker than you? This number is a percentile, and works for any quantity/trait that can be compared. If you’re better at giving advice than 85 of the 99 other people, then you’re an 85th percentile advice-giver.
Is that person beautiful or ugly? Are they good at playing the piano? How smart are they? Is a person gregarious or shy? Do they know French? Do they have health problems? A world of nuance opens up when one starts thinking in percentiles and other numbers, rather than just being restricted to categories.
This sort of thinking also applies to objects, events, groups, et cetera. Is Russia a poor nation or a rich nation? Is that an expensive brand of soap? Are dolphins intelligent? Was the war of 1812 justified? Each of these questions is best answered by a number, rather than a simple binary. (Deeper answers than “40th percentile” are good, of course, but communication is about efficiency. Sometimes it’s useful to be able to give the short answer.)
There are biases and traps that people fall into when doing this kind of thinking, such as failing to choose the right reference class, or not really having a good sense of what random people are actually like. But it’s not like avoiding numerical thinking helps solve these issues — numeracy is simply not the end of the road of better-thinking. In general, using percentiles and other numbers expands one’s awareness of the world and helps break stiff categories into smooth quantities.
Probabilisitic Reasoning
Our beliefs can be wrong, which is why it’s important to anchor opinions to bets. But as it turns out, the ratio at which a bet changes from positive in expectation to negative in expectation is exactly the probability of the event that the bet is based on. Probability is in the mind — it’s the measure of our uncertainty.
Numerate people understand that their subjective feelings of confidence correspond to numbers, and work to train themselves to automatically connect the two. Instead of saying “I’m 100% confident,” a person who has developed this skill will say things like “I’m 90% confident,” and understand the difference.
Learning to connect subjective confidence with numerical probability is something that can be trained relatively easily in most people, but few ever put in the time to build it as a skill. A person who is wrong one time out of ten when they say “I’m 90% confident” (for example) is said to be “calibrated.” Calibration training can be done just by testing oneself on basic questions until the instantaneous feedback reliably indicates that probability estimates line up with frequency of getting it right. I like this web app, but there are many.
Probabilistic reasoning doesn’t just apply to yes/no questions, either. When someone gives a numerical estimate, it’s better to interpret it as the average of a distribution, like a normal distribution. Of course, just by itself, the average isn’t sufficient to communicate how confident/precise one’s estimate is. The typical way of including confidence is for the estimator to give a range, and indicate a probability that the true value is in that range. For instance, when making the garbage estimate earlier, I could have said “My 67% credible-interval is between 0.34 and 34 billion liters/day.”

One must be careful not to confuse a credible interval, like we’ve been talking about, with a confidence interval, as is more typically used in scientific papers. A confidence interval is a confusing and poorly-understood statistical technique that resembles the p-value in being simultaneously very popular and quite bad.
{kind=link}
The takeaway from the common use of confidence intervals and p-values, for me, is that we live in a society that is so innumerate, even most scientists don’t understand probabilistic reasoning. Proper understanding of probabilities isn’t hard, but it requires an emphasis on numeracy that our civilization lacks.
Utopian Numeracy
A true Utopia is a society where more than 95% of (human) children learn to use and understand quantities to the point where they are deeply numerate. This numeracy is not about being able to do algebra, trigonometry, or even arithmetic, but rather about feeling like 1296, 7776, and 46656 are intuitively distinct and meaningful quantities, such that if someone were to offer a lottery ticket with a 1/1296 chance of winning, the Utopian could easily conceptualize that as distinct from a ticket with a 1/46656 chance of winning.
Utopians are numerate enough that they mostly don’t think in terms of essential categories, but rather in terms of orderings and distances. There is no debate as to whether penguins are birds or Pluto is a planet, because it’s understood that all patterns outside of formal systems are fuzzy, and allow for edge-cases. Utopians understand the problem of reference classes, and deliberately train themselves to accurately describe random members of various groups that are established through social consensus as useful classes to be aware of.
Confidence intervals and p-values aren’t used in Utopia. Instead, scientists are expected to publish likelihood ratios and raw data. Some scientists choose to share their prior and posterior belief-distributions, but it’s not expected.
Children are trained to calibrate their subjective-sense of confidence with numerical probabilities, and how those probability numbers line up with optimal betting strategy. This calibration is reinforced by a norm of quizzes requiring the answerer to provide probabilities (or very commonly: odds) on their answers, where multiple answers can usually be given (sometimes with a small penalty). Quizzes are then graded using a proper scoring rule that encourages honest probabilities to be given by more sharply punishing confident mistakes than rewarding confident correct answers. As a result, test-takers can be evaluated both on what they know and how well they know it.
For instance, an oral examiner might ask a child as part of a chemistry test what chemicals are produced when sugar fully burns. They might answer that they put “5 weight on water and carbon dioxide, 1 weight on water, some carbon dioxide, and some carbon monoxide, and 3 weight elsewhere.” This means they’re betting with 5:4 odds (56%) on their first answer, 1:8 odds (11%) on their second answer, and 3:6 odds (33%) on the last answer. The examiner might judge the correct answer to be the first one, and award the child more points than if they’d been wrong, but less points than if they’d been more confident. The teacher would then also have the opportunity to talk about complete versus impartial combustion to clarify why the second answer wasn’t more correct.

Early physics classes often have you plug numbers in on the homework. But they have you do them by giving you big chunky numbers in SI units and so you can end up not knowing the scale of any of the numbers. If you have good professors later on, you will get to see the true joy of being able to roughly calculate the answer, and the way it lets you roughly understand the scale of things.
Some notes about physicsy numbers (I have memorized most of the numbers that I pull out of thin air, whereas anything I calculate is probably at best only roughly remembered):
The meter was originally defined as 1 millionth of the distance from the equator to the pole. So the circumference of the Earth is about 40 Mm (megameters, or thousands of km). You can then get that the radius is 6.5 Mm.
The Karman Line is a convention for the start of space, 100 km above sea level. A picture from space will see the airglow at about that altitude. The Armstrong limit is the altitude at which water boils at human body temperature (though you'll still die at lower altitudes unprotected), and is about 20 km which incidentally is about where the troposphere ends and the stratosphere begins. Commercial flights fly at about 10-15 km up.
An astronomical unit (sun-earth distance) is about 500 light seconds, or .15 trillion meters. The moon is like 1 light second away. Now look at scale model of the solar system https://solar.heimerng.dev/ . The Earth is tilted relative to the solar system by about 23 degrees, useful for astronomical calculations like predicting where stuff will be in the sky.
The gravitational constant G is very small. It's also hard to measure. Much easier to measure is G M where M is the mass of the Earth. This is because GM/R^2 = g, where R is the radius of the Earth and g is the gravitational acceleration on Earth (about 9.8 ≈ 10 m/s. It varies by location by up to almost 1%). So GM = 420 Trillion (m^3/s^2). To find M, use the fact (which Newton guesstimated surprisingly accurately!) that the average density of the Earth is about 5 times that of water (water has a density of 1 g/cm^3 = 1 g/mL = 1 kg/L = 1 ton/m^3, which originally was how the kilogram was defined) (additionally, air's density is about a thousandth of water). From this you can find the volume (1 trillion trillion m^3) and mass (6 trillion trillion kg) of the Earth, and then the gravitational constant (about 70 per trillion in SI units).
Any physicist should know that the speed of light is very close to 3 * 10^8 (that is, 300 million) meters per second. This is about a foot per nanosecond. Funnily enough, this is how I remember that a foot is .3 meters. For the wavelength of visible light: green is 500 nm, +200 on the high end and -100 on the low end. Same is true for frequency, but this time in THz. You can check that 500 nm * 500 THz = 2.5 * 10^8 which is close to the speed of light. Visible light photons have an energy of about 2 (+1 on the high end, -.5 on the low end) eV. It takes like a dozen eVs to free electrons from metals.
Refractive indices are in a small range: water and glass are like 1.5, and at the high end diamond is like 2.5. Gases are very close to 1.
I can never remember the value of the (reduced) plank's constant ħ, the basic constant in quantum physics. It was amazing when a professor in a nuclear physics class gave me the following mneumonic: the product ħc is about 200 MeV fm (fm is femtometer, that is, 10^-15 meters). This is useful because I know how big c is, so whenever ħ pops up I can multiply and divide by c.
The binding energy, as any physicist knows, of a ground state electron in the hydrogen atom is 13.6 eV (that is, electron volts). You can just remember "a dozen". Thus, chemistry happens on the energy scale of 1-10 eVs. Likewise, our electron is .5 Angstroms away from the nucleus (an angstrom is .1 nanometers). So, chemistry happens on the scale of angstroms. X rays can probe things like crystal structure because they have a wavelength of around an angstrom (.1 nm, so frequencies of exahertz (10^18) and energies around 10 keV). Molecules tend to be that big. Proteins are more like dozens of angstroms, though and "weighs in" at 50k daltons (the mass of an atom in daltons/atomic mass units is about the number of nucleons it has, e.g. carbon-12 is 12 daltons) due to having like 5k atoms. There is an distinction in medicine/biology between "small molecules" (with <500 daltons) and "big molecules" like proteins.
Electrons bop about on the order of attoseconds (10^-18) (e.g. the time for a bond to form), while reactions happen on the order of hundreds of femtoseconds (10^-21, or 1k attoseconds). Femtosecond and even attosecond laser pulses can be made.
The molecules rotate and vibrate at energies on the order of meV, which is why infrared spectroscopy allows us to learn about that. Ultraviolet light at the far end can get high enough to ionize the electrons, starting at about 10 eV (100 nm or 1 PHz)
The electrostatic force/energy between two charged particles is given by coulomb's law. In SI units Coulomb's constant is 9 GJ m/Coulomb^2. For atomic physics, it's more useful to know that this is about 1 eV nm/e^2 (e is the magnitude of the charge of an electron). This tracks with the way that chemistry involves eVs and nms. Incidentally this is one way to remember how big an electron's charge, but instead I prefer using the Faraday constant: a mole (6 * 10^23) of electrons has about 100 kC of charge. Thus you can get that an electron has about 100/6 * 10^-19 = 1.6 * 10^-19 C.
A mole is the number of hydrogen atoms you need to have a gram of hydrogen, and thus converts between daltons and grams and is used a lot in chemistry. Numerically, it is about 6 * 10^23.
For the magnetic force: The vacuum permeability mu_0 is about 4 pi /10 micro Henries/m. The force between two infinitely long wires is the product of their currents times mu_0/(2 pi), that is, about .2 micro newtons per meter. "micro" is often denoted with the same greek letter, mu, which might help you remember.
Ferromagnetic core solenoids can't get above about 2 Tesla because of magnetic saturation. More than that and you are probably using a superconductor. You can levitate a frog with 15.
Nuclear physics happens on the scale of MeV. Binding energy differences per nucleon are a few of those, and this is why nuclear reactions are so powerful (e.g. fission for uranium-235 is 215 MeV). Gamma rays are often in the range of MeV As for size, nuclear physics happens on the femtometer (10^(-15) m) scale.
High energy physics smashes particles together and makes new ones. Electrons are .5 MeV in mass, while protons and neutrons are 1 GeV. The up and down quarks are a couple MeV, strange is like 100 MeV, and the rest are in the GeVs, which is why strange quarks show up more often.
In thermodynamics, the boltzmann constant comes up a lot. It converts between temperature (in kelvin. room temp is 20 C = 293 K) and energy. The "mole version" of it converts between temperature and the average energy of a mole of particles, and is called the ideal gas constant R. This is about 8 Joules/Kelvin/mol. Using this you can figure out that the boltzmann constant is on the scale of 10^(-23) in SI units. You can remember that at room temperature a monatomic ideal gas atom will have an average energy of 3/2 k_B T = 50 meV (actual number is 38), or alternatively that k_B T = 25 meV, and now you have a way to figure out how big an eV is. A mol of gas atoms will have 3/2 R T = 3.5 kJ of average energy, or in other words RT = 2.3 kJ at room temperature.